首先尝试了build-emacs-for-macos这个辅助编译的脚本,它会帮你安装需要的依赖,编译过程还算顺利。但是发现它编译出来的emacs有点诡异。
打开Emacs后,会提示几个包的代码有些问题,这在我的预期之内。升级完Emacs,已经安装过的包最好都升级一下,或者删掉重装。因为老版本的emacs生成的elc文件,新版本不一定能兼容,就会出现各种奇奇怪怪的问题。
把有问题的包升级完,再重启emacs,问题依然存在。这就不符合预期了。索性把所有安装的包全部删掉,再重新安装。这样操作之后,再启动Emacs,看起来好像没问题了。
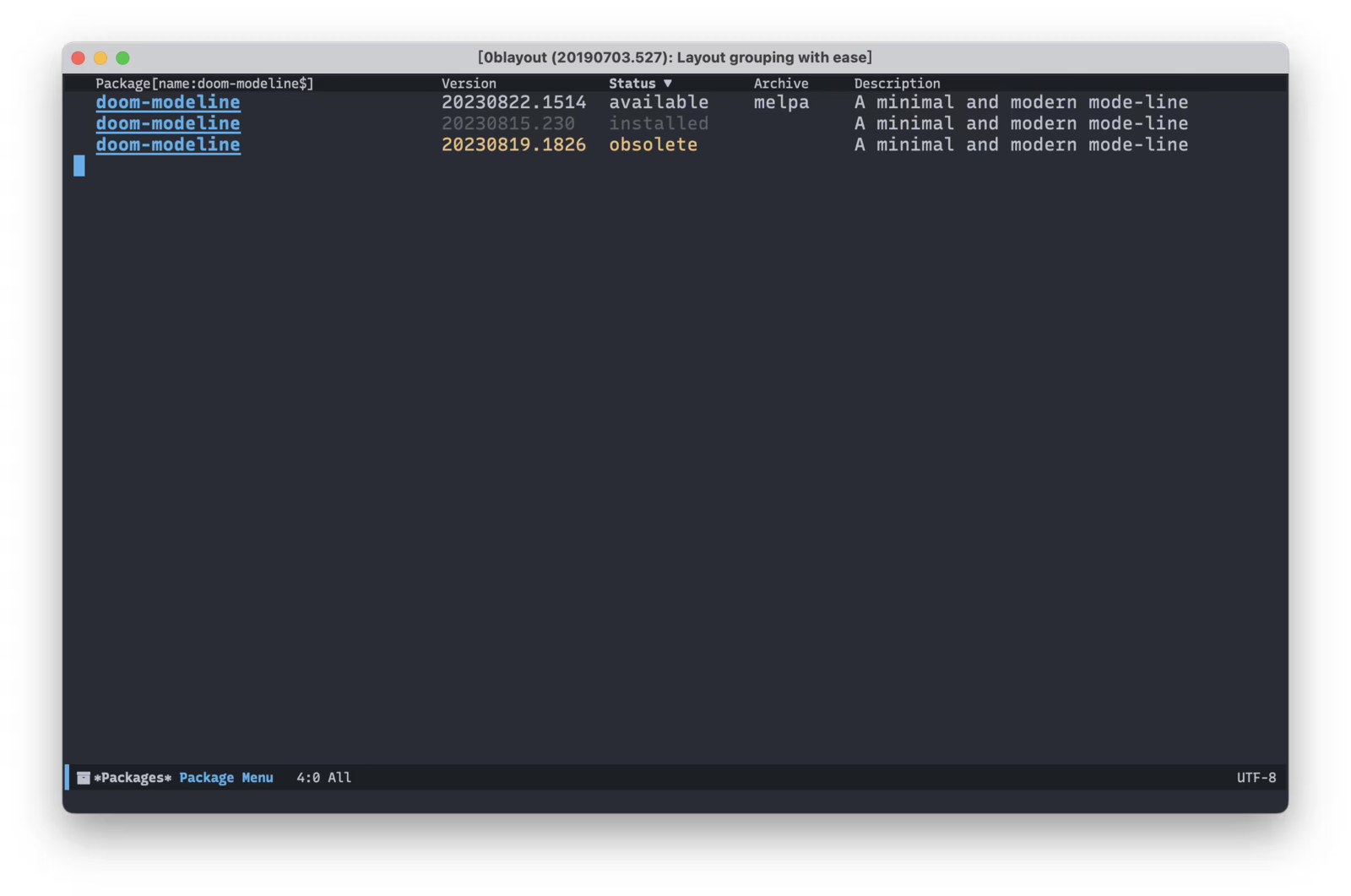
用了几天之后,诡异的问题又来了。有些包又有新版本,升级完重启后,发现依然使用老版本的,新版本被标记为obsolete。比如上面的doom-modeline,明明 20230819.1826 这个才是新版本,但生效的却是 20230815.230 。这个问题浪费了很多时间,我都开始看package.el代码,怀疑是不是Emacs 29本身带来了什么问题。
命令行是我们与程序之间最基础最朴素的交互方式,命令行参数是工具的灵魂,程序的功能有很多,指定不同的参数可以实现不同的功能。我写过无数解析命令行参数的代码,大部分都非常简单,满足基本功能要求即可。最近刚好需要实现一个相对复杂的命令行工具,简单的解析无法满足需求。因此重新考察了几个命令行参数解析库,做一下横向对比。
因为主要开发scala的程序,这里仅讨论适用于JVM的库。包括scopt、mainargs、scallop和picocli。对比下来,picocli完胜。
命令行解析的需求
最开始并不清楚自己的需求到底是什么,这些库看起来都挺好,没什么区别。在实际开发的过程中,就逐渐发现这些库的缺点。好的命令行解析库应该满足下面这几点要求:
Emacs的书签非常好用,通过它可以非常快速地跳转到对应位置。虽然使用 ivy-switch-buffer 已经可以非常快速地切换文件。但是书签跳转还要更高效一些:
-
书签精确到行级别,通过书签可以直接跳到某个文件的某一行。也可以给不同的行设置书签,然后在不同的行之间来回跳转。
-
有些文件路径非常深,记不住文件名和路径,不能通过 ivy-switch-buffer 快速的找到。这时候就可以记录一个书签,起个好记忆的名字,或者给书签打上tag。
Emacs原生书签功能相对简单,因此我使用了 BookmarkPlus,它在原生的基础上做了很多扩展,比如支持给书签打tag,支持函数的书签,支持书签的注释等等。
随着日常使用的积累,书签越来越多,书签的搜索成了一个大问题。一直用 counsel-bookmark 来搜索书签,但它只能按书签名称进行搜索:

书签多了之后经常忘记名称,找不到想要的书签,counsel-bookmark的功能就显得有些鸡肋。其实除了书签的名称之外,文件路径、书签tag都是非常重要的信息,如果把这些内容综合起来再搜索,只需要记得其中一项就可以匹配,效率会高很多。
TL;DR
本文讲述如何用Alfred实现更高效的窗口切换,Workflow地址:https://github.com/jxq0/alfred-app-switcher。
效果如下图所示,按下F1切换到Firefox,F2切换到Emacs,F3切换到iterm2。可以在Workflow中自定义快捷键与对应的App。

我的日常工作离不开浏览器书签,书签和笔记一样,也属于个人知识管理。如果不用书签,工作方式可能是这样的:
-
前几天同事刚发了一份腾讯文档,需要看的时候要么打开聊天记录找,要么在腾讯文档里面找。要么为了下次不再找,不关掉浏览器的tab,直到打开了几十个tab不得不关。
-
进入内部系统的某页面,先输入内容搜索,但是搜索非常慢,进入页面要等半天。
-
同样是搜索的场景,但是搜索的“关键字”需要查一下代码才知道,比如系统内部id。
非常不喜欢这种“前戏”太多的工作方式,为了完成一个工作,需要先做另一件繁琐的操作,效率极其低下。
浏览器书签可以解决这些问题,但是浏览器的书签功能用起来非常不爽。

自身的变化
近来发现对许多事情都提不起兴趣,心里有点慌,难道是抑郁症的前兆?转念一想,我只是对那些“建设性”的事情不感兴趣而已,吃喝玩乐还是很感兴趣,于是松了一口气。
摄影曾经是最喜欢的事情,不怕苦不怕累,凌晨四点起床去深圳湾拍日出,扛着三脚架去深圳和香港的大街小巷,拍了很多满意的城市风光照片。但近几年摄影频率大幅度降低,一年才会拍一次,三脚架也很久没动了。今年夏天天气很好,非常适合拍照,内心有一点躁动,想要去拍。但是最终还是没有行动,要么因为太困早上起不来,要么是觉得去了也不一定能拍到好的照片。本质的原因还是因为没有动力了。即便拍到好的照片又能怎么样呢,我的生活会发生变化吗?拍了这么多年,我的Instagram粉丝数依然少的可怜。想到这里,就像气球被扎破,一瞬间所有的乐趣都没有了。除了摄影之外,还有很多东西也不再有吸引力。比如对技术不再好奇和狂热,“新兴的语言和工具都是玩具而已”。