基于org-mode、markdown和alfred的高效书签工作流

我的日常工作离不开浏览器书签,书签和笔记一样,也属于个人知识管理。如果不用书签,工作方式可能是这样的:
-
前几天同事刚发了一份腾讯文档,需要看的时候要么打开聊天记录找,要么在腾讯文档里面找。要么为了下次不再找,不关掉浏览器的tab,直到打开了几十个tab不得不关。
-
进入内部系统的某页面,先输入内容搜索,但是搜索非常慢,进入页面要等半天。
-
同样是搜索的场景,但是搜索的“关键字”需要查一下代码才知道,比如系统内部id。
非常不喜欢这种“前戏”太多的工作方式,为了完成一个工作,需要先做另一件繁琐的操作,效率极其低下。
浏览器书签可以解决这些问题,但是浏览器的书签功能用起来非常不爽。
首先,在浏览器里找书签是件非常痛苦的事情,体验远远达不到要求。当有十个几十个书签的时候,在书签工具栏里面点开找一找是ok的,但如果书签增加到上百个,再点开书签栏去找就很难了。
所以我更希望能直接在地址栏搜索书签,比如url或者书签名字,就可以快速精确的匹配到对应的书签。也许是因为我用Emacs久了,习惯了“指哪打哪”的体验,再回到浏览器的搜索上,体验的差距就非常明显。Chrome的搜索非常鸡肋,一定会匹配单词的开头。比如Subprocess,如果输入subp,可以正常返回,但如果输入process,就搜索不到了。如果是中文,Chrome会先分词,再进行如上的匹配,中文的问题更明显。
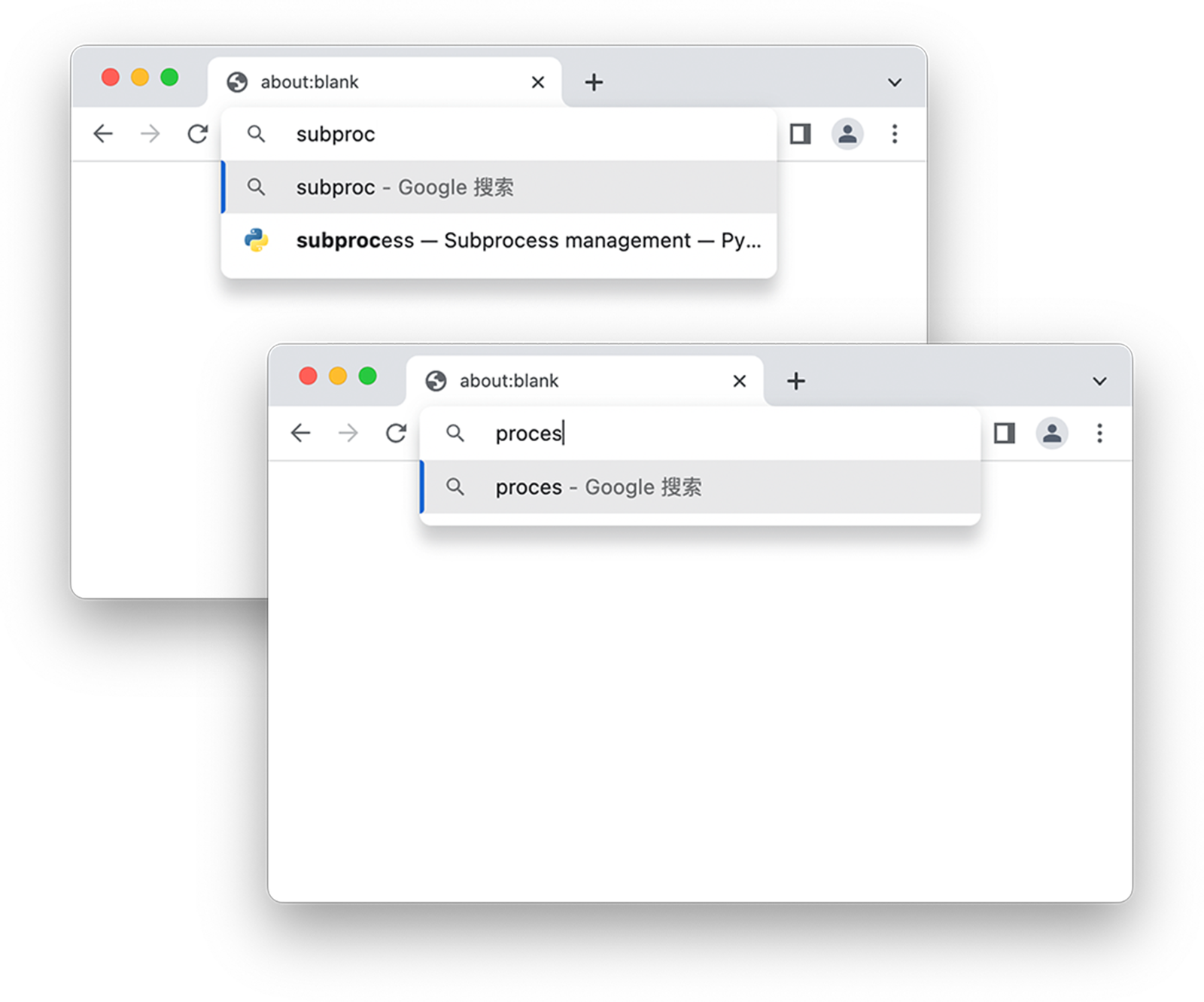
相比之下,Firefox的搜索就好用一些,无论从哪个字符开始都可以正常匹配。但无论是Firefox还是Chrome,都不支持用拼音来搜索汉字。搜索书签的时候还要先切到中文输入法,再输入对应的汉字,这样又增加了一些额外的步骤。如果把“哔哩哔哩”作为书签的名字,我希望输入“blbl”或者“bl”就能匹配到。
另外浏览器内不支持用书签文件夹的名称搜索。很有可能记不住具体书签的名字,但是文件夹很容易记忆。如果能展示出某个文件夹下的所有书签,再来选择就简单多了。
第二,在不同的机器和不同的浏览器之间同步书签是个难题。如果只用一个浏览器,这并不是问题。但对于多浏览器的用户来说就很难了。除非每次都在一个浏览器添加书签之后,再手动导入另一个浏览器,步骤过于繁琐,很容易就遗漏了。
基于以上的痛点,我开始探索一种更高效的书签管理和使用方法。
探索一:使用org-mode管理书签
跨浏览器的书签不方便同步,那是否可以用文本文件来保存书签,通过git或者网盘来自己实现同步?文本文件用什么格式,很自然的就想到了Emacs的org-mode。
工作流就变成了维护一个书签的org-mode文件,每次需要访问书签的时候,只需要打开这个文件,然后找到对应的链接回车即可。把这个文件放到git上,同步的问题就解决了。而且不再依赖任何的浏览器,不管想用哪个浏览器,都可以找到需要的书签。
使用org-mode还有个好处是可以非常灵活的调整书签的层级结构,不过就是调整某些行的位置。
存储书签的org-mode文件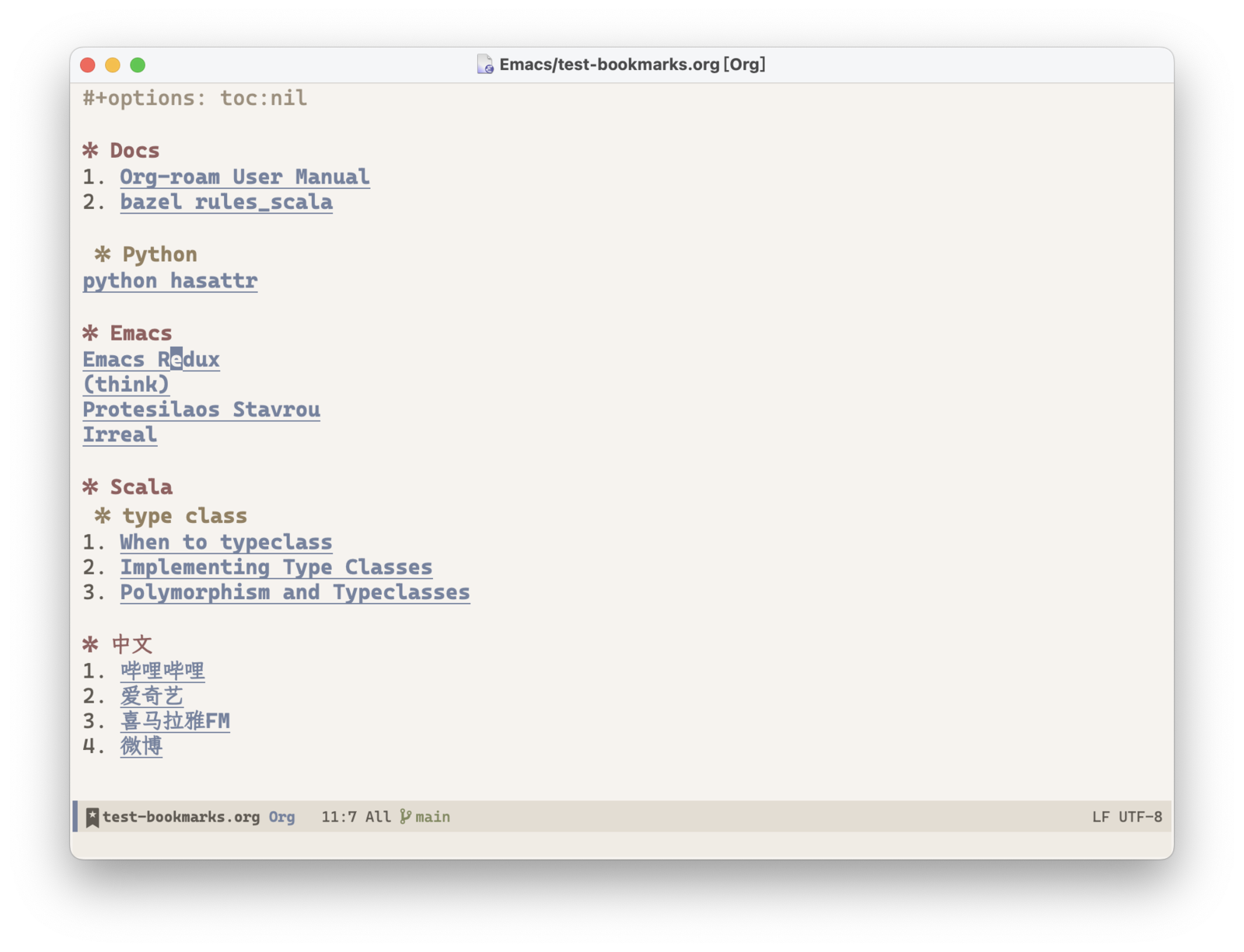
但是依然很慢。每次需要的时候还要先打开这个文件,再找到对应的行,比用浏览器慢好多倍。
探索二:将org-mode中的书签导入浏览器
书签最终还是要在浏览器里面访问的,org-mode只适合存储书签,但并不适合直接用来访问。能不能把org-mode的书签导入浏览器中呢?因此我实现了 jxq0/org-bookmarks-extractor 这个emacs lisp package(我第一个发布到melpa上的package)。
这个包是这么实现的:
-
通过org-element-api,解析org-mode文件。
-
递归遍历解析好的数据结构,在遍历的过程中选出url链接,并记录下org-mode的heading层级结构,作为浏览器书签的文件夹。
-
按照浏览器导出的书签格式来生成html文件。
在浏览器里选择导入html文件,就可以访问这些书签了。
org-mode书签导入chrome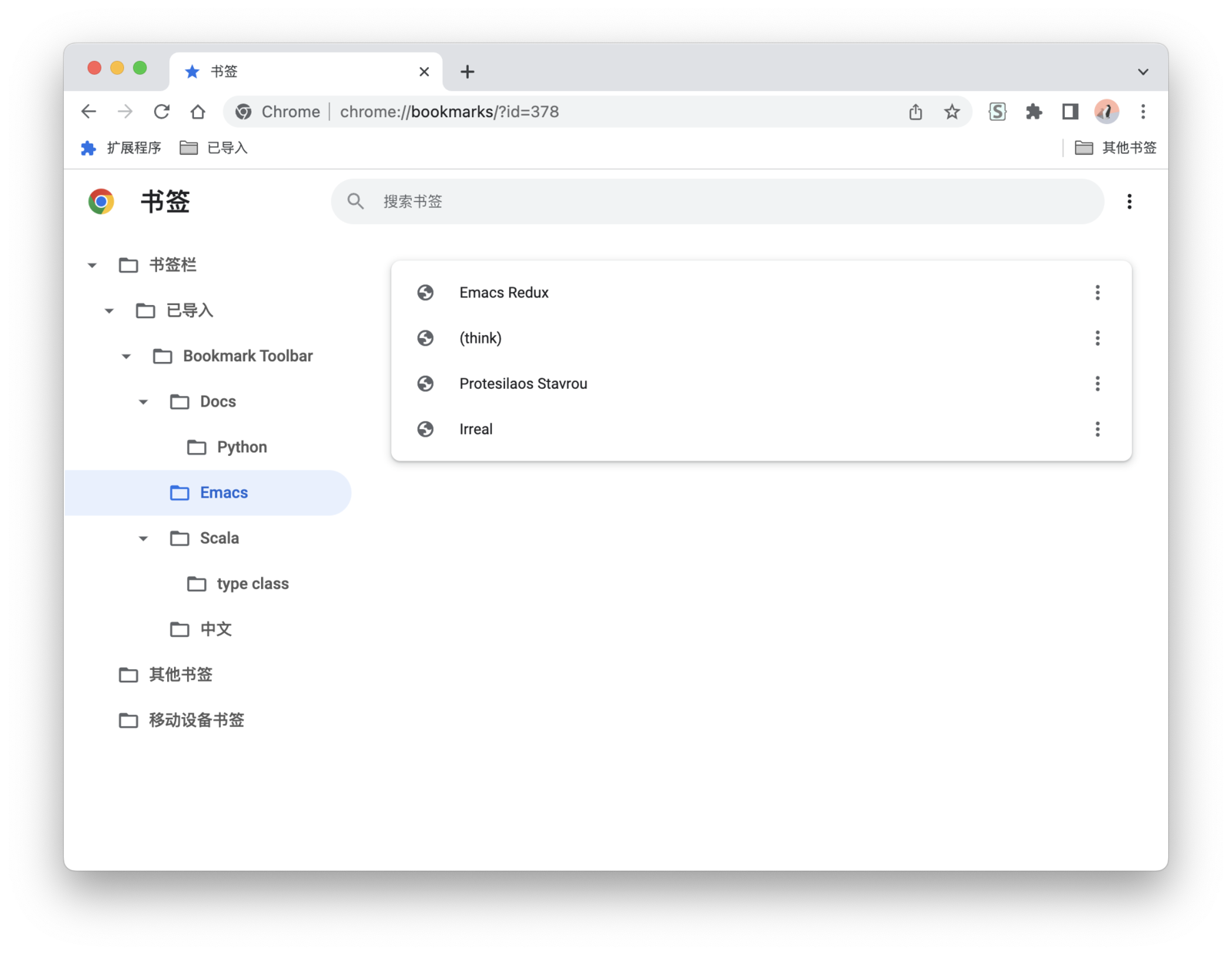
但是后来发现即便有了这个包,书签的搜索和访问效率依然没有提升。这一步探索其实是走了不必要的弯路,只是在第一步的基础之上优化,没有从根本上解决搜索的问题,意义不大。
终极方案:alfred-smart-bookmarks
Mac的用户应该对Alfred不会陌生,它可以说是一个万能的搜索入口,不管是搜文件还是应用都非常高效,同时又具备高度的可扩展性,这点类似Emacs,所以我非常喜欢这个应用。如果用抽象的思维来看,Alfred的逻辑是极其简单的:输入关键字,返回一个结果列表。某个关键字应该展示什么结果,这里的花样就非常多了。更多的入门使用方法可以看这篇文章:总是在 Mac 「装机必备」看到的搜索利器 Alfred,究竟是怎么用的?
Alfred本身是支持搜索浏览器书签的,但是它的搜索体验依然存在前面那些问题,不过好在我们可以开发workflow来定制搜索的行为。
项目地址是jxq0/alfred-smart-bookmarks。主要有以下特性:
-
支持搜索org-mode或者markdown文件中存储的书签。
-
兼容Chrome或者Edge浏览器的存量书签,如果你在浏览器里已经维护了大量的书签,在没有工具的情况下一次性全部迁移到文本文件工作量也是非常大的。所以这个workflow也支持搜索浏览器中的书签。
-
强大的搜索体验:
-
全文搜索,不再强制匹配单词,不论是搜“subp”还是搜“process”,都可以匹配到“subprocess”。
-
可以按拼音或者拼音首字母搜索。如果想搜“哔哩哔哩”,输入“bl”即可。
-
一切内容皆可搜索,包括书签地址、书签名称、org-mode或者markdown中的各级标题,浏览器的书签文件夹名称等等。
-
通过多个关键词精简候选列表。这个特性借鉴了Emacs中的ivy。当你输入一个关键词,却发现返回的结果很多,难以找到自己想要的那个书签,这时你只需要再继续输入其他的关键词,就会匹配到同时满足这多个关键词的结果。
-
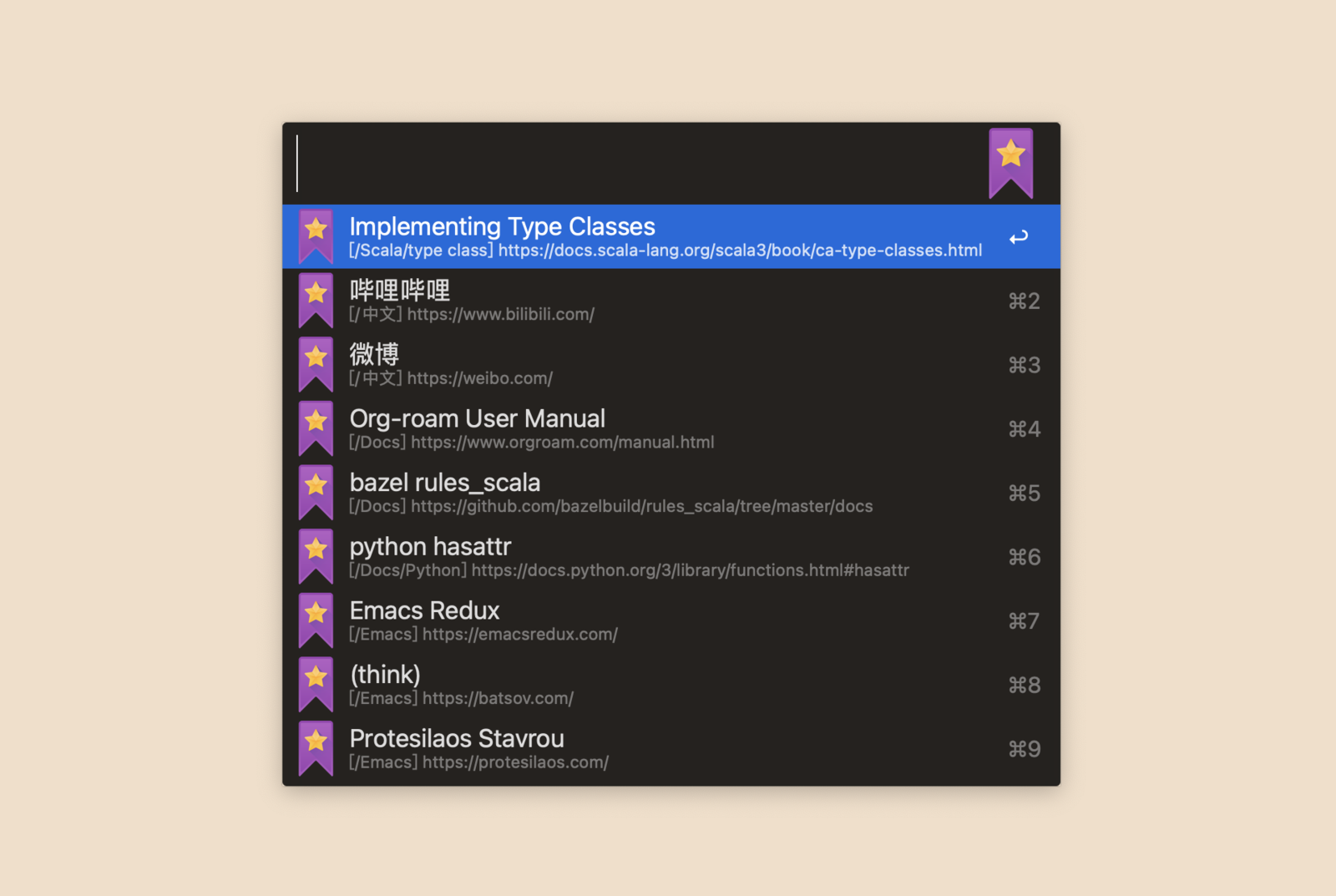
这些特性描述起来可能没什么感觉,安装体验下就知道有多么丝滑了。需要先安装三个python包: pip install orgparse pinyin mistletoe 。然后在release里面下载最新版,双击就会打开alfred自动安装。安装后需要做一些简单的配置:
-
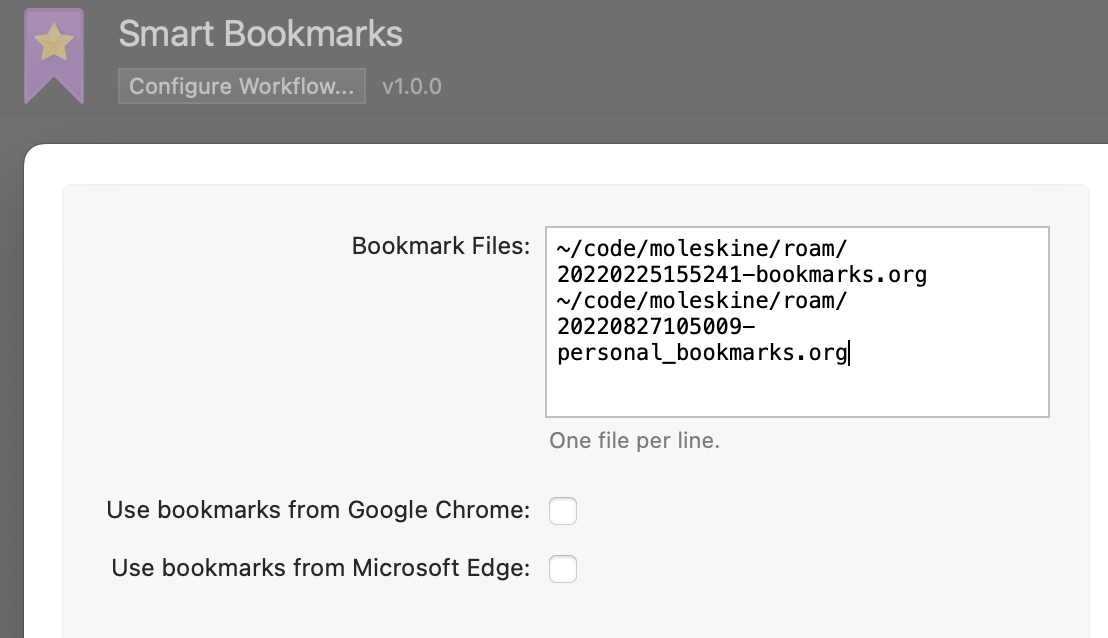
点击Configure Workflow配置你的org-mode或者markdown文件所在的路径。以及是否需要从浏览器读取书签。
-
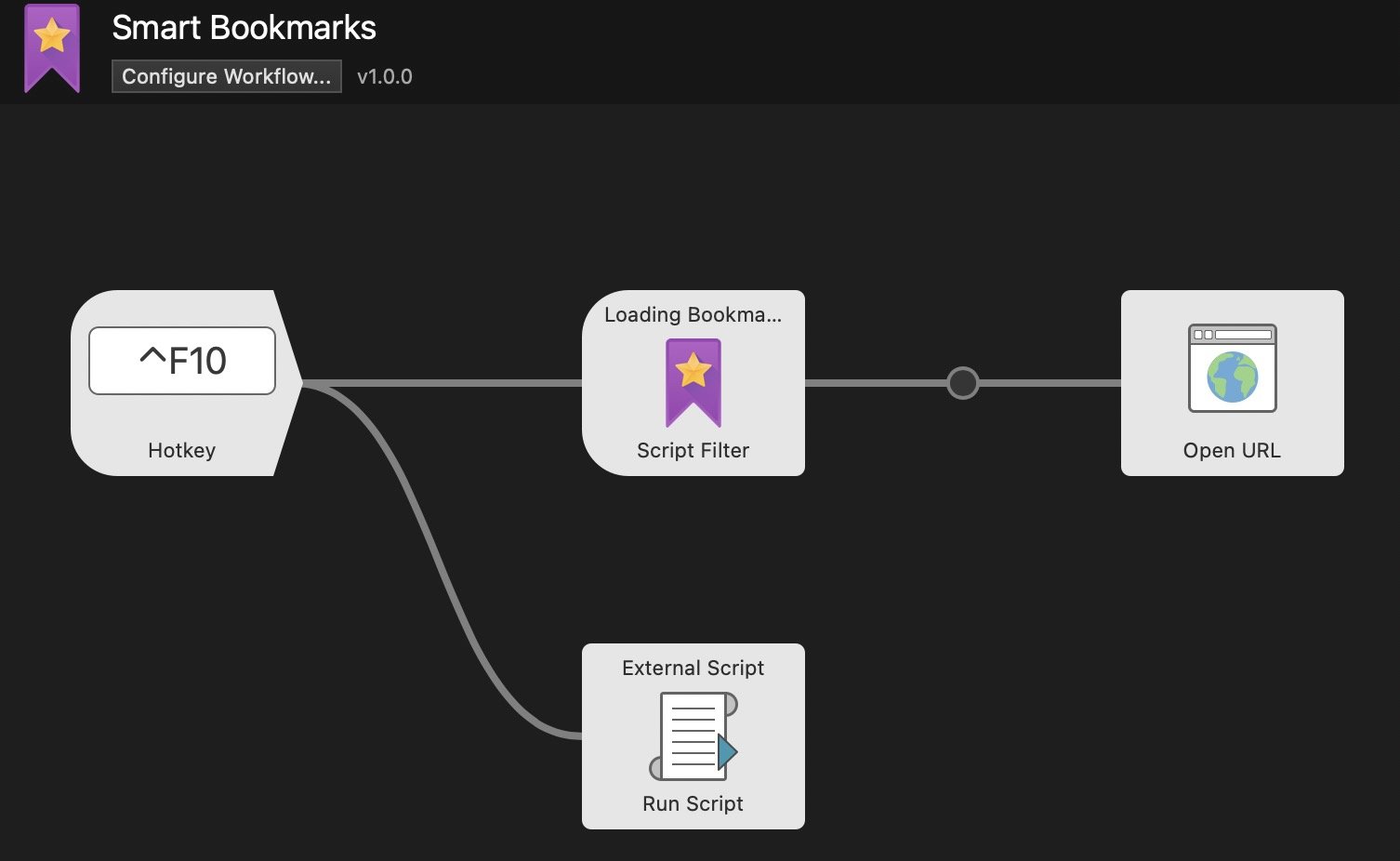
给workflow分配一个快捷键,比如我用
ctrl+F10。按下快捷键就可以打开alfred搜索书签了。
一些实现细节
workflow的开发门槛非常低,就是一个简单的脚本,按照alfred的格式返回json就可以了。alfred-smart-bookmarks目前是用python和js实现的。将来可能会改为rust,在面向普通用户的场景下Python还是不太合适,需要用户安装几个包,这就有一定的门槛了。还是用二进制来分发更好一些。
使用了orgparse和mistletoe来分别解析org-mode和markdown文件。通过pinyin来做汉字到拼音的转换。
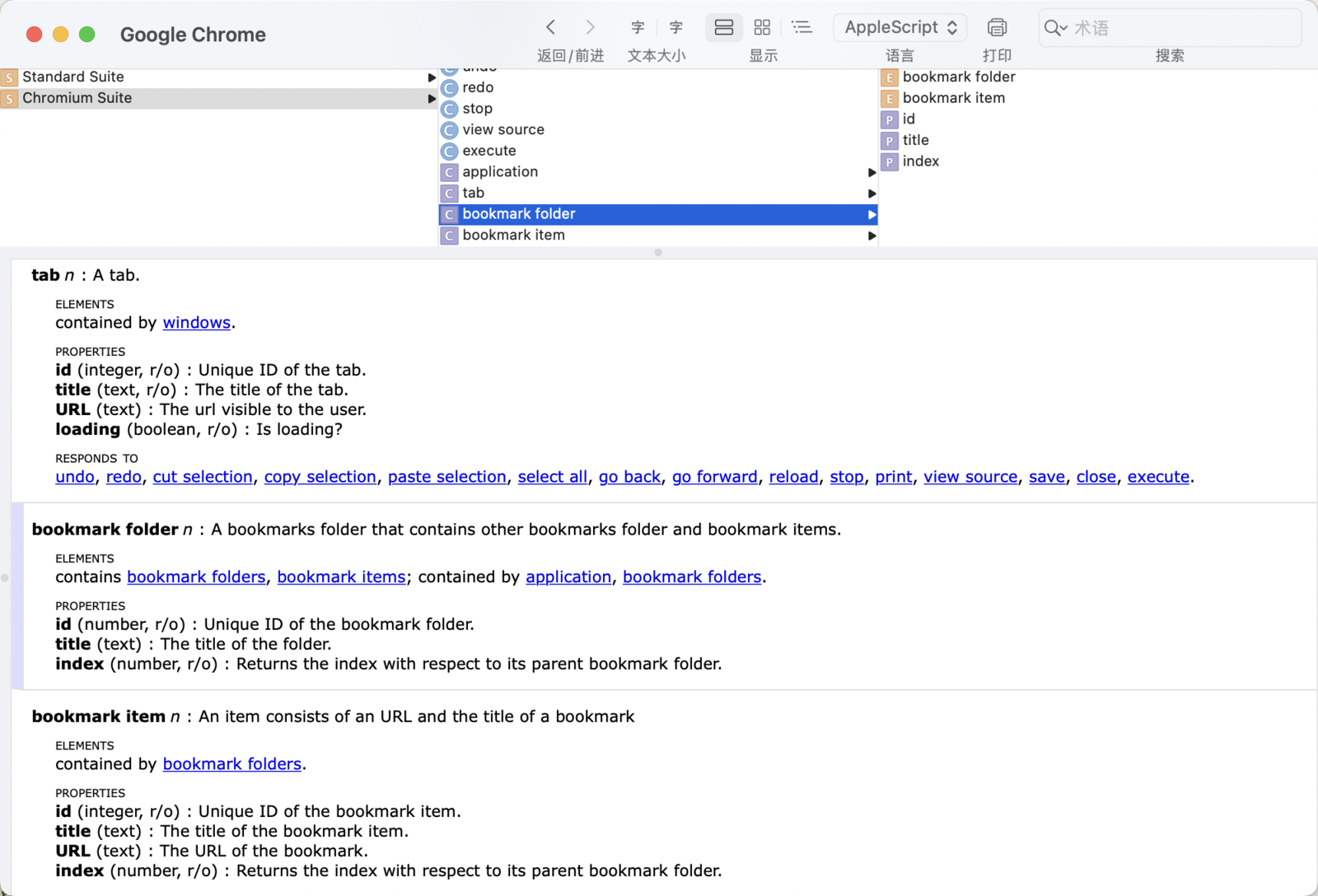
浏览器的书签搜索是通过osascript实现的。这也是为什么只支持了搜索chrome或者edge书签的原因。因为Firefox没有实现api。发现osascript的功能还是挺强大的。如果想看某个App有开放了哪些api,可以打开系统自带的“脚本编辑器”,然后选择“文件”菜单中的“打开词典”。比如chrome提供的书签相关的api: