数据工程师的“最后一公里”
作为一名数据工程师,我经常处理“大”数据。但有时候也需要处理“小”数据。比如通过大数据计算得到的一些相对“小”的数据结果,还需要进一步的统计分析。如果再用大数据的框架跑一遍计算,非常浪费资源浪费时间。效率最高的方法还是在本地就把这些数据处理了。
这类数据处理场景就像送快递,包裹跨越万水千山终于到了目的地城市。这时候应该选择什么交通工具来把快递送到你的手上呢?长途和短途所选择的交通工具肯定是有差别的。在这种“小数据”的场景下,什么工具才是效率最高的?为了解决数据分析领域的“最后一公里”问题,我尝试了很多种工具,但总觉得不太顺手。因此实现了 ob-pyspark-sql 这个 org-mode 扩展包,解决自己的痛点,提升工作效率。
尝试过的工具
Excel 或者 Numbers
人人都会用 Excel,这是最简单直接的方法,应对简单的数据分析完全够用。更高级的数据处理 Excel 也是可以做到的,但有一定的学习成本。对我个人而言,没有动力去学这些高级的用法。学习 Excel 花费的时间,自己写代码都能解决了。
Excel 和 Numbers 给人的印象如同大象,体积庞大并且笨重。为了看一个很小的数据还要打开这种庞然大物,对本不富裕的系统资源来说就是雪上加霜。另外,有些“小”数据可能也很大,超过 100 万行的数据用 Excel 处理是非常吃力的。
Visidata
Visidata 是 python 写的一个命令行 ui 工具。界面简洁,支持多种数据格式,csv、json、excel 文件都可以打开。常见的数据操作如排序、过滤、聚合都不在话下。
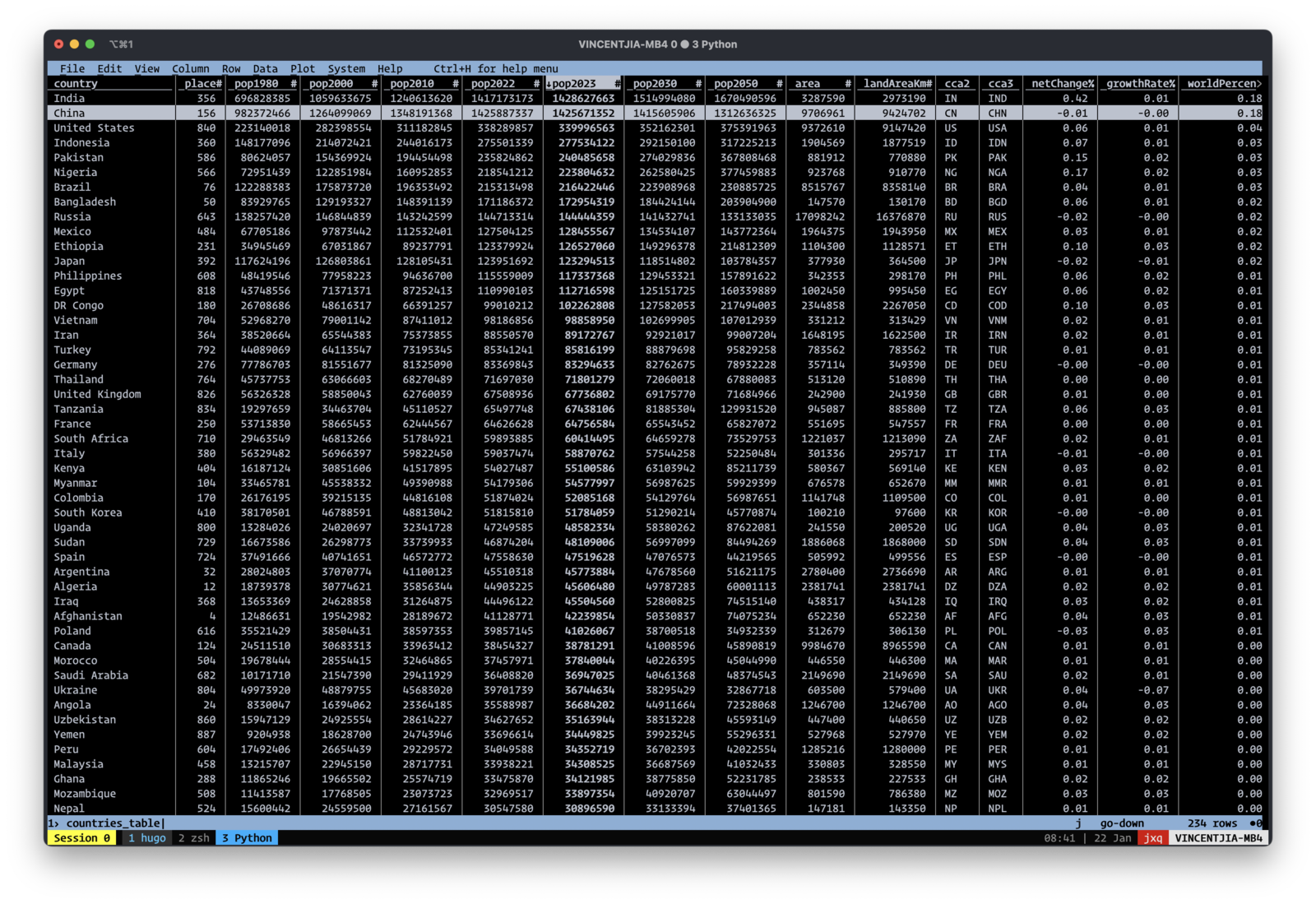
Visidata 的命令行 ui 非常的优雅,类似于 vi,用户体验很好。有段时间我尝试只用 visidata 来做数据分析,但最后还是放弃了。它的优点也同时是它的缺点。命令行界面体验好,但要在命令行界面实现复杂的数据分析,意味着需要非常复杂的快捷键。而学习这些快捷键的时间成本,丝毫不亚于学习 excel,甚至比 vi 还要复杂。每次分析些复杂的数据,都要查文档才能知道要按什么键。比如,要按某一列聚合求和,需要进行以下操作:
-
移动到需要求和的列。
-
按
#键将列修改为数值类型。 -
按
+键增加 aggregator,选择 sum。 -
移动到需要聚合的列,按
SHIFT+F。
要记住这一系列操作步骤很难,使用起来还是过于复杂,因此 Visidata 不适合做数据分析。但如果只是想看看数据长什么样,Visidata 还是很好的工具,它的速度比 Excel 可快多了。
支持 sql 的命令行工具
Spark
Spark Sql 是数据工程师必备技能。如果能在本地用 Spark Sql 来分析小数据,最好不过了。不需要担心语法不一致的问题,没有额外的学习成本。
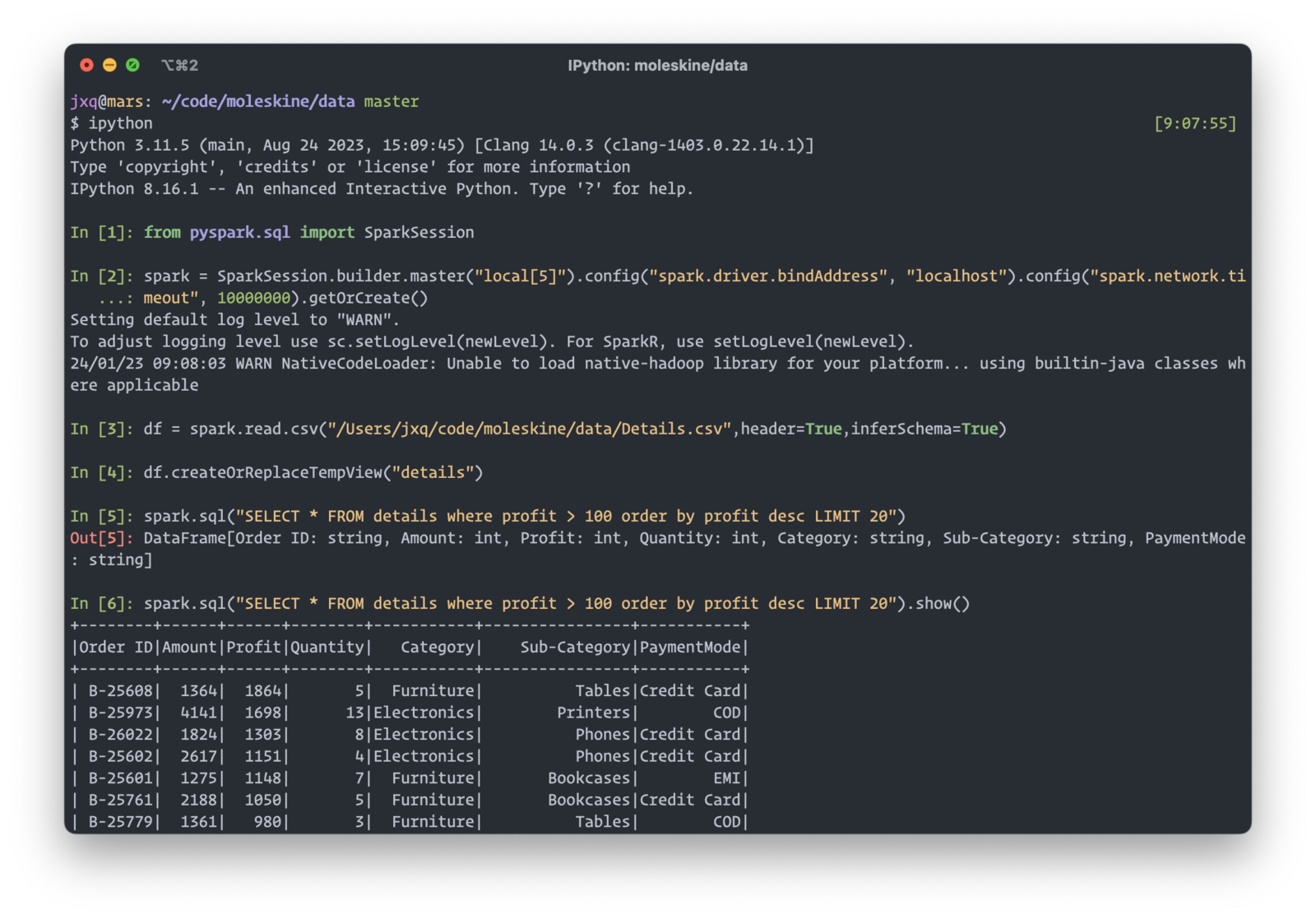
在本地跑 spark 很简单,但这种方式需要一些前置工作,比如创建 spark session、读取文件、注册临时表等等。即便把这部分代码封装起来,还是有额外的步骤,不够直接。分析数据的时候一有思路就希望马上就得到结果,这些前置工作会让人分心,回过头来可能刚才的灵感已经忘记了。在命令行里面写复杂的 sql 也比较难受,没法格式化 sql,长的 sql 语句阅读性很差。
渐进式的数据分析过程
在多数人的认知里,数据分析是一锤子买卖,一次操作就能得到最终结果。但实际上数据分析是渐进式的,基于一份原始数据,通过不同视角得到多个中间数据。再基于这若干中间数据才能得到最终的结果数据。走一步看一步,只有看到中间的数据才有下一步的分析思路。
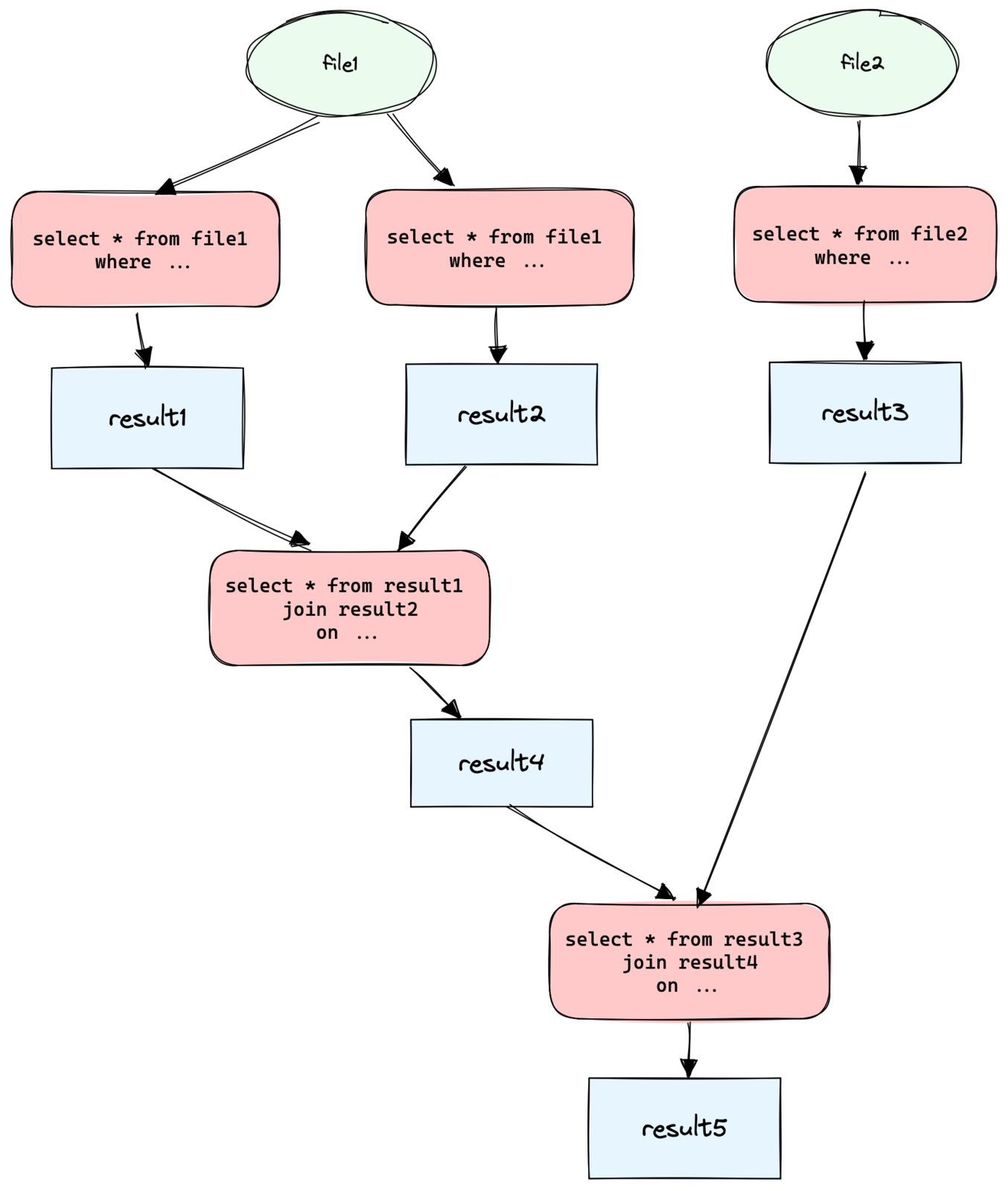
上面列举的工具都只适合做一锤子买卖,比如 ipython 里面跑 spark,会话关掉后计算的代码和数据都没了。结果数据和计算逻辑没有保留下来,也就没法复现整个数据分析的过程,将来复盘数据的时候,都不知道自己是怎么计算的,只能从头开始。
最理想的工作方式是一边整理文档一边分析数据,在文档中记录分析的思路,我为什么要这么计算,这个结果说明了什么问题,下一步应该怎么做。同时,直接在文档中执行 sql 计算,结果直接输出到文档。所有的工作都在这一个文档中搞定,用户不需要切换到其他地方跑数据。这就是“交互式笔记”的概念。这类产品有 Jupyter 和 R Markdown,但它们都不是纯文本的格式,不能在编辑器里写,也很难做版本控制。
基于 org-mode 的交互式数据分析
作为 emacs 用户,我希望在 emacs 里完成所有的事情,很自然的就想到了 org-mode。org-mode 里面可以插入代码块,而且这些代码块是可以执行的。在 emacs 里这叫做 文学编程,其实跟“交互式笔记”一个意思。org-babel 自身已经包含了大多数语言的实现。
现在的问题是,如何在 org-mode 里面执行 spark sql ?org-mode 的可扩展性非常强,底层的代码很完善,参考其他语言的实现很容易就可以自己写一个,比如在 org-mode 里面执行 python 代码是通过 org babel python 实现的,核心的函数是 org-babel-execute:python 。
再回到需求本身,我想要的是在 org-mode 里插入 sql 代码块,然后把这段代码发送到 spark 上执行。既然 org-mode 已经支持 python,只需要把前面我们在 ipython 里跑的代码封装好,把 sql 传递进去,然后再调用 org-babel-execute:python 就可以了。
基于这个思路,我实现了 ob-pyspark-sql 。目前还没有提交到 melpa,可以手动安装。
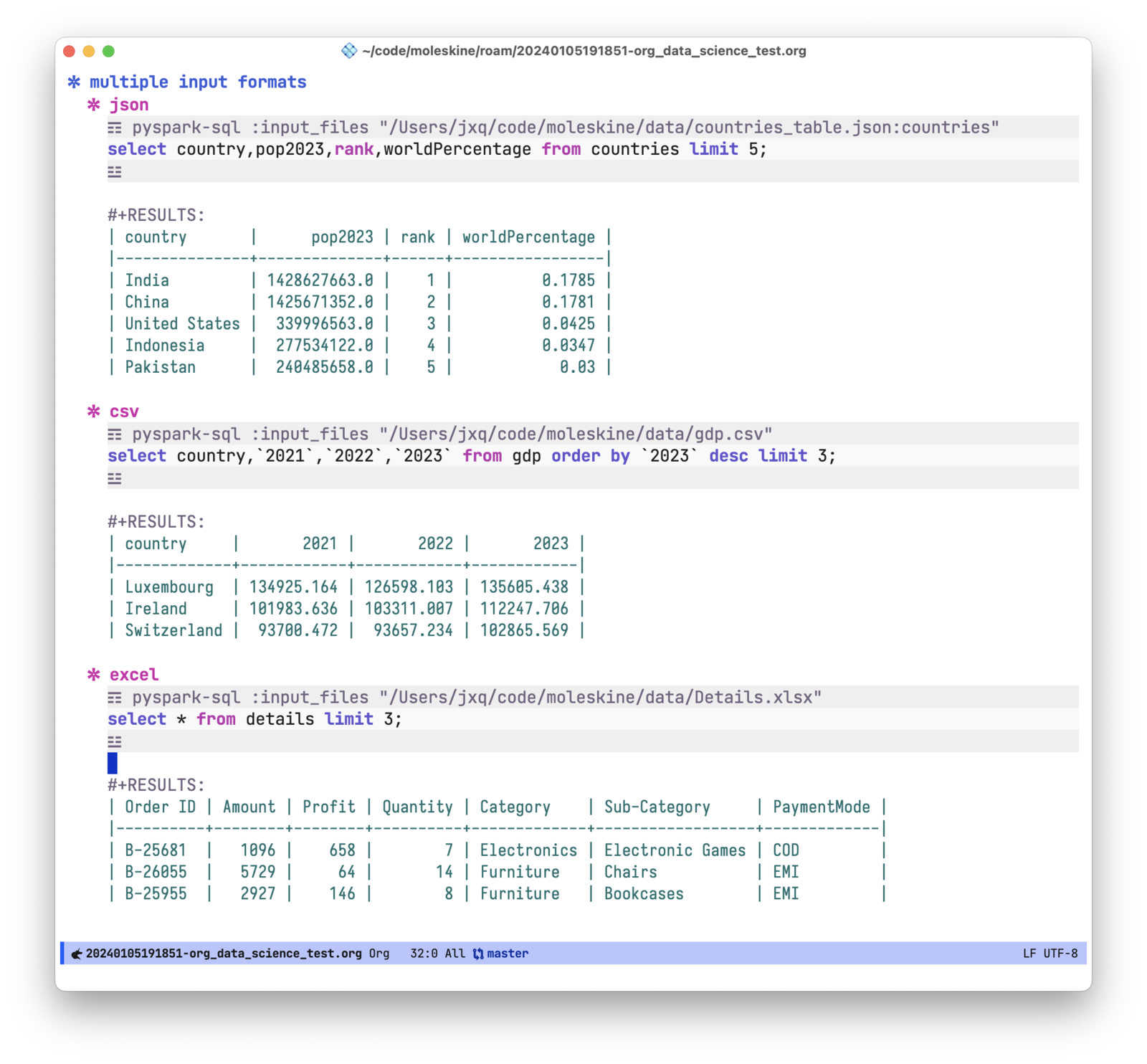
支持各种数据格式
通过 :input_files 指定原始的数据文件路径。参数中 : 之后的部分为导入 spark 的表名,如果不指定则默认取文件的 basename 作为表名。
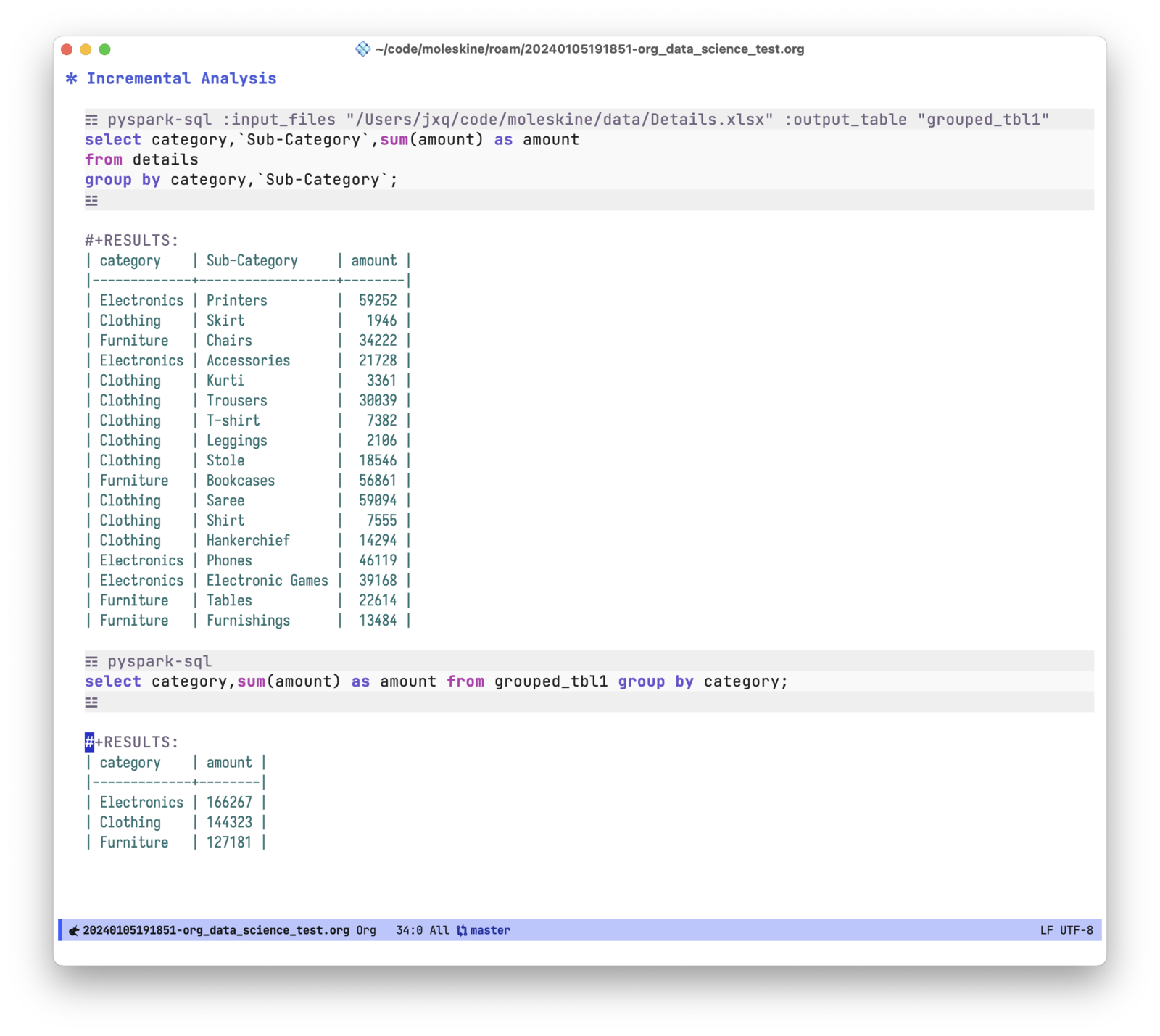
渐进式分析
有了 ob-pyspark-sql 就可以实现渐进式的分析。在原始的数据上执行计算,把结果保存到 spark 表中,再继续基于这个结果表执行新的 sql。通过 :output_table 这个 header 参数指定结果所存储的表名。
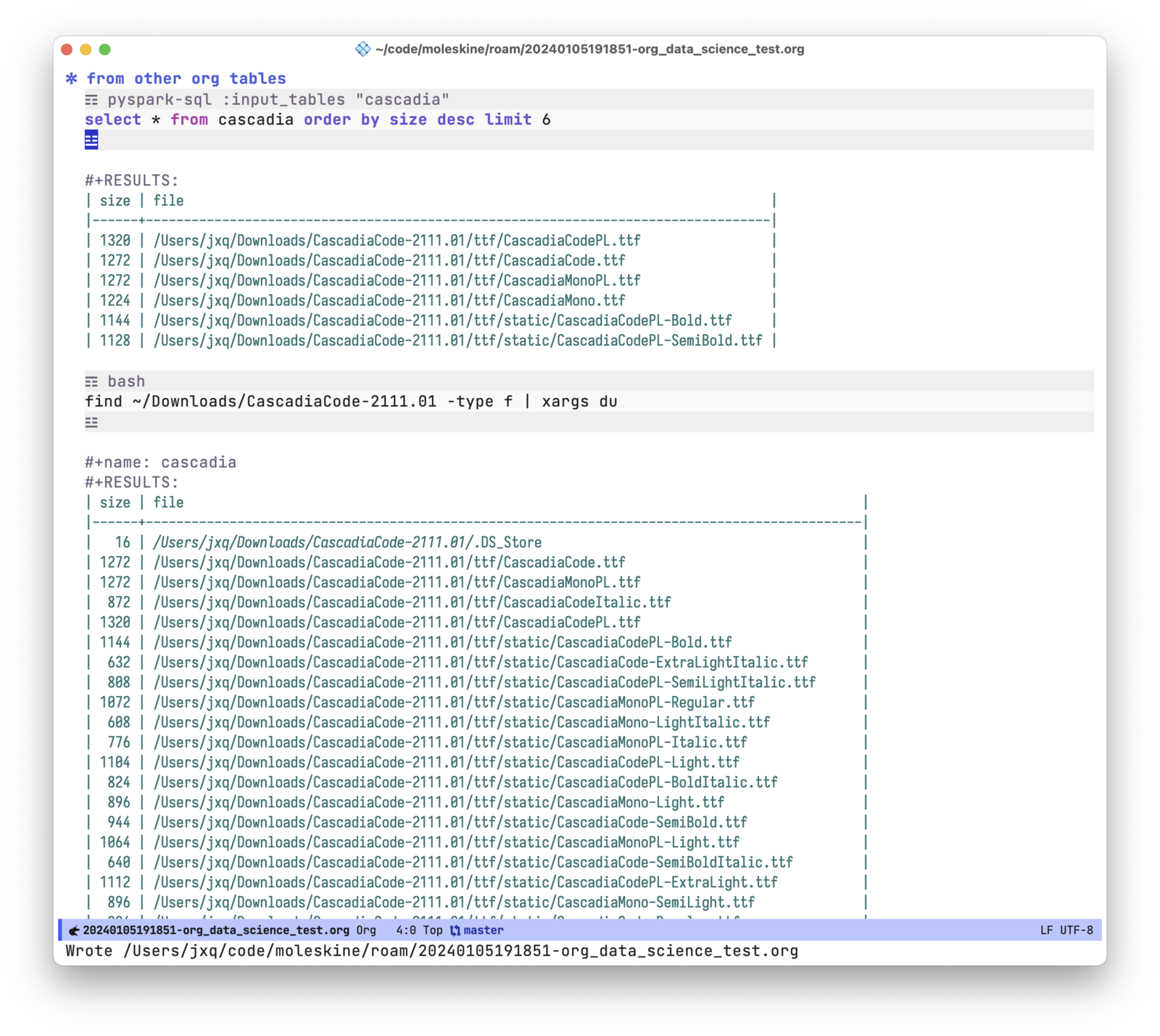
把 org table 作为数据源
数据源不一定全部来自文件,也有其他的 org table。ob-pyspark-sql 支持把其他的表格作为数据源。通过读取 org table ,能处理什么样的数据完全取决于想象力了。比如,可以在 org-mode 里先执行 bash 命令,然后在命令的结果上跑 sql。
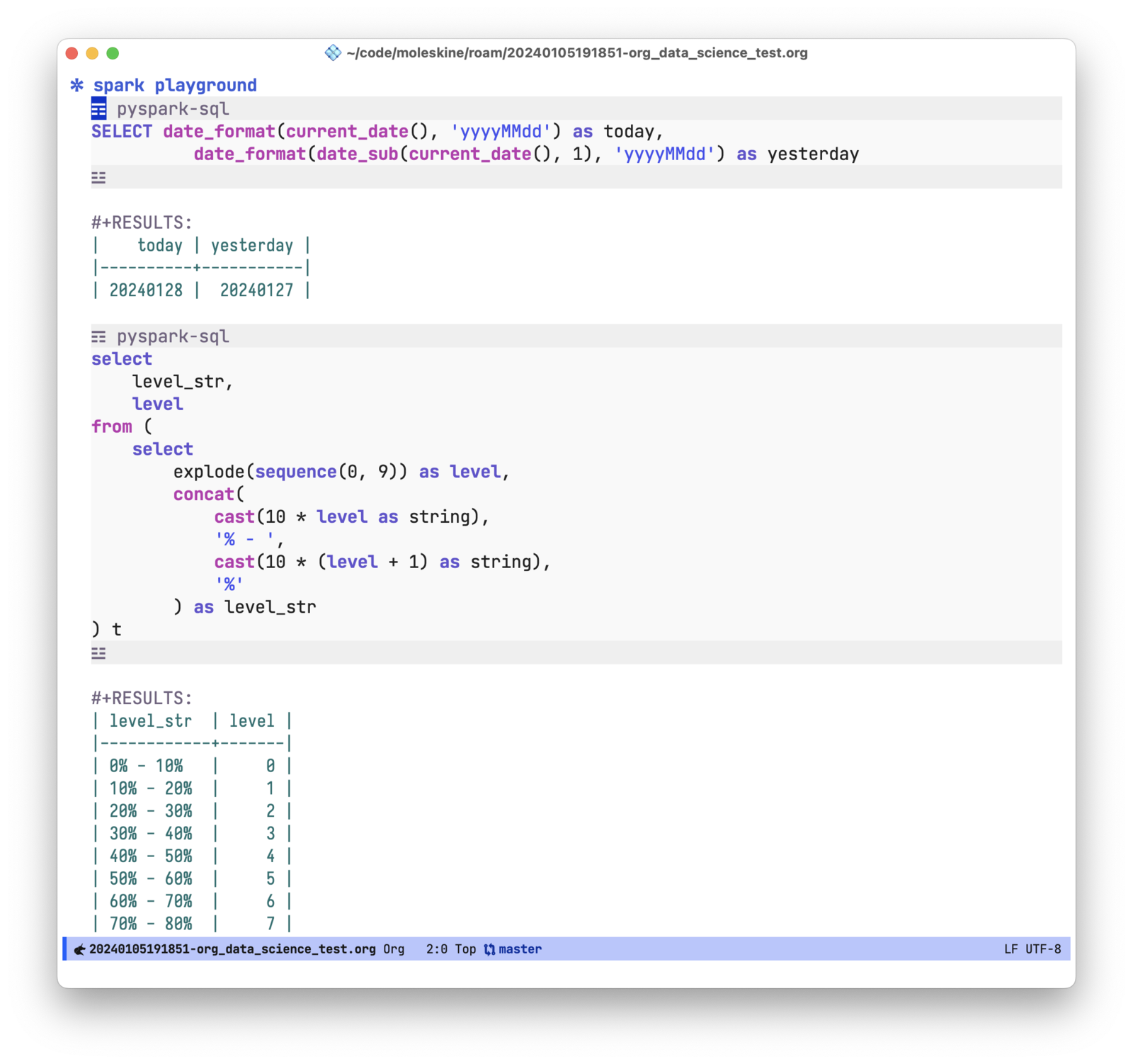
作为 spark sql 的 playground
对某个 spark sql 的函数不熟悉的话,可以把 ob-pyspark-sql 当做测试的 playground,在里面快速验证这些函数的使用方法。如下图分别使用了 spark 的日期处理、explode 和 sequence 等函数。
数据可视化
分析完数据后,我们往往希望用一种直观的方式来呈现数据,即数据可视化。数据可视化的方法有很多,python 的 matplotlib,r 语言的 ggplot,js 的 echart 等等。数据可视化的自由度很高,难以做统一的封装,因此 ob-pyspark-sql 没有实现这部分功能。如果是用 python 来做可视化,可以通过 get_df 这个函数更方便地获取 dataframe。比如,各国家人口数量的可视化。
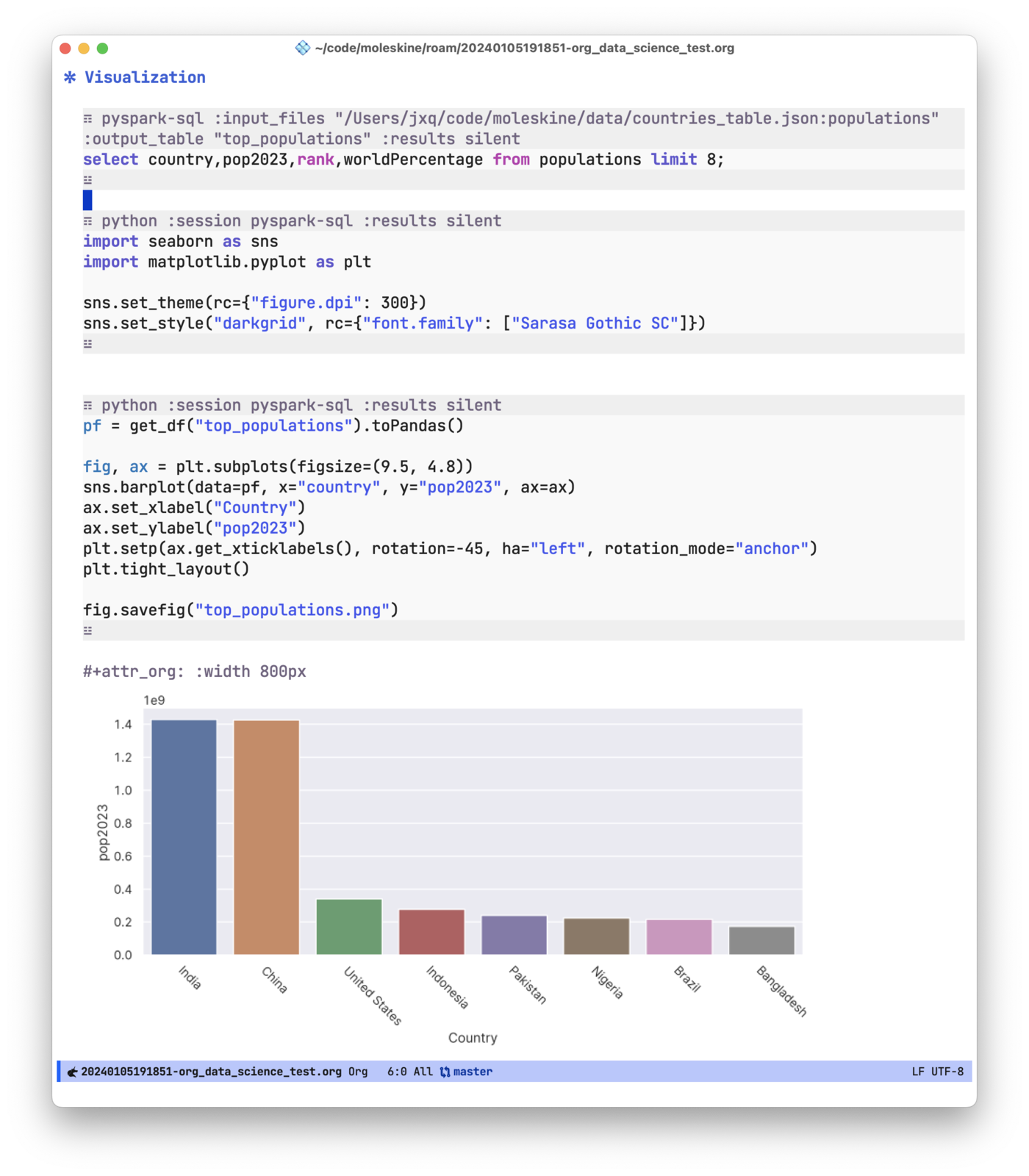
实现 ob-pyspark-sql 之后,我已经很久没用过 excel 了,所有的工作都在 emacs 里面完成。如果你也是 emacs 用户并且需要分析数据,不妨尝试一下 ob-pyspark-sql 。